Failover WorkFlow
4.3.0.1 Failover
replication-manager is checking all master failures up to N times, and when all false positive checks pass, the default behavior is to send alerts and put itself in waiting mode until a user forces the failover or that the master self-heals.
This default is know as the On-call mode and configured failover-mode = "manual"
Failover can be continue via user interaction with the console, the web server on default URL http://replication-manager-host:10001/, the API or the command line client.
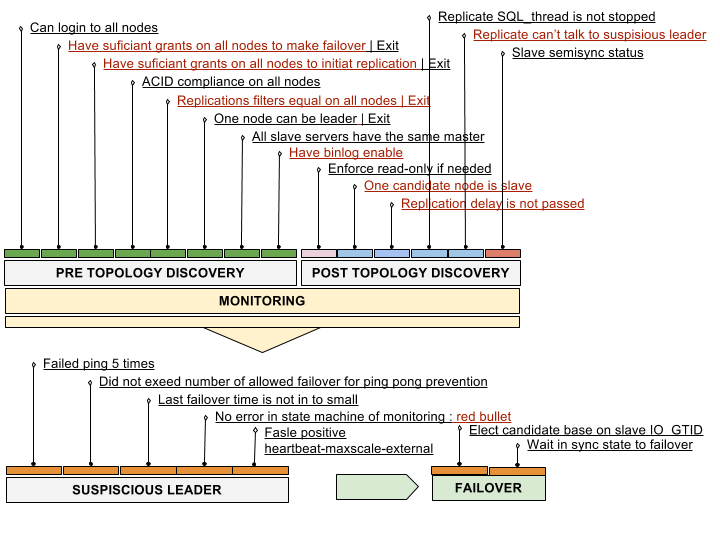
Conditions for a possible failover are constantly monitored.
- A valid slave need to be available and up and running.
- The cluster configuration needs to be valid.
Note: the definition of a valid slave is influenced by the prefered or ignored servers but since replication-manager 2.0 we first look at the most up to date position in all slaves. After founding this it can eventually say that failover is impossible because none of the slaves with highest position match the constraints , if multiple slaves have that same highest position, than the prefered master can be considered as a valid candidate.
Some users define failover replication constraints that can be added in the configuration file.
- Exceeding a given replication delay
failover-max-slave-delay - Time interval between failovers
failover-time-limit - Number of Failover can be limited
failover-limit - Synchronous state of the replication is lost
failover-at-sync
We strongly advise to set the following best practice configuration in automatic failover:
failover-limit = 3
failover-time-limit = 10
failover-at-sync = false
failover-max-slave-delay = 30For minimizing data lost in automatic failover:
failover-at-sync = true
failover-max-slave-delay = 0A user can still force failover by ignoring replication checks via:
check-replication-state = falseThis can be dynamically changed via the HTTP interface "Replication Checks Change" button.
Per default Semi-Sync replication status is not checked during failover, but this check can be enforced with semi-sync replication to enable to preserve OLD LEADER recovery at all costs, and not perform failover if none of the slaves are in SYNC status.
A user can change the sync check based on what is reported by the SLA in-sync metric, and decide that most of the time the replication is in sync, and when it's not, that the failover should be manual. Via http console, use the Failover Sync button.
All cluster down condition leads to a situation where it is possible to first restart a slave previously stopped before the entire cluster was shutdown, failover in such situation can promote a delayed slave by a big amount of time and lead to as much time data lost. By default replication-manager prevents such failover for the first slave unless you change failover-restart-unsafe to true. When using the default, it is advised to start the old master first, if not replication-manager will wait for the old master to show up again until it can failover again.
The previous scenario is not that frequent and one can favor availability in case the master never shows up again. The DC crash would have bring down all the nodes around the same time. So data lost can be mitigated if you automate starting a slave node and failover on it via failover-restart-unsafe=true if the master cannot, or takes too long to recover from the crash.