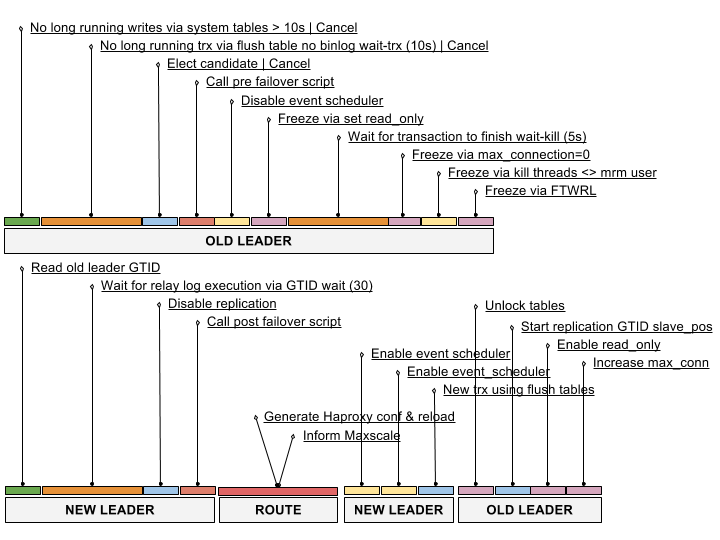
Switchover Workflow
4.2.0.1 Switchover Workflow
replication-manager is starting up with checks to disable potentially dangerous switchover cases. It looks for some excessively long WRITE queries, excessively long transactions and cancel the switchover in such case. Switchover also follows the state machine blocking states so that malfunctioning replication or wrong topology also will not enable switchover.
During switchover, replication-manager prevents additional writes via setting READ_ONLY flag and FTWRL on the old leader, if routers are still sending WRITE transactions, they can still pile up until timeout. To prevent this, replication-manager kills those blocked transactions.
Some additional caution to make sure that piled writes do not happen is that replication-manager decreases max_connections to the server to 1 and consumes the last possible connection by not killing himself. This works fine in practice, but to avoid a scenario where a node is left in such state where the database cannot be connected anymore (killing replication-manager in this critical section), we advise using extra port provided with MariaDB or MySQL pool of threads feature:
MariaDB Thread Pool
thread_handling = pool-of-threads
extra_port = 3307
extra_max_connections = 10To better protect consistency it is strongly advised to disable SUPER privilege on users that perform writes, such as the MaxScale user used with Read-Write split module is instructed to monitor the replication lag via writing in the leader, privileges should be lower as described in Maxscale configuration settings.
4.2.0.2 Switchover Events Graph